
微软将DeepSeek-R1 7B和14B版引入Copilot AI PC 使用NPU单元在本地运行
#人工智能 微软将 DeepSeek-R1 7B 和 14B 版引入 Copilot+PC,让用户可以通过本地 NPU 单元运行 AI 模型,无需联网和调用 API。不过现阶段这些模式本地运行速度还是很慢的,1.5B 能 40tokens / 秒,而 14B 版速度仅为 8tokens / 秒。查看全文:https://ourl.co/108165
2025 年 1 月微软就计划将 DeepSeek-R1 模型的 NPU 优化版引入搭载高通骁龙 X 处理器的 Microsoft Copilot PC,到本月初微软发布了经过微调的 DeepSeek-R1-Distill-Qwen-1.5B 版。
现在微软宣布通过 Microsoft Azure AI Foundry 为这些 AI PC 带来 DeepSeek-R1 7B 和 14B 精简版模型,让这些 AI PC 可以通过 NPU 单元在本地运行 AI 任务不需要联网进行运算。

由于模型是在本地 NPU 单元上运行的,用户可以持续获得 AI 计算能力,既不需要通过调用 API 付费,也可以通过本地运行延长续航时间,同时 CPU 和 GPU 还可以做其他事情。
微软推出的这些模型是通过内部自动量化工具 Aqua 将所有 DeepSeek 模型变体量化为 int4 权重,不幸的是模型 token 速度非常低。
根据微软自己的测试,14B 版速度仅为 8tok / 秒,而 1.5B 版可以 40tok / 秒,这个速度相对来说还是比较慢的,微软希望在后续继续优化模型提高速度。
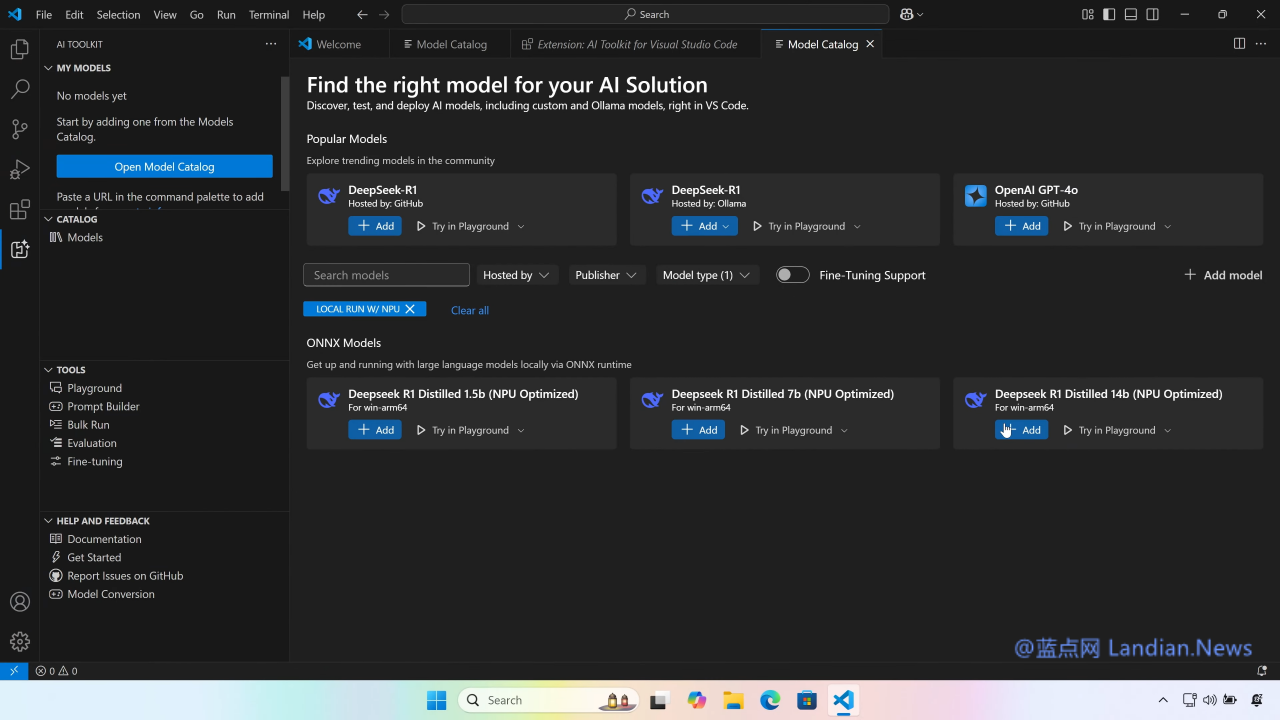
另外现在所有开发者都可以通过 AI ToolKit VS Code 扩展在 Copilot+PC 上下载并运行 DeepSeek 模型的 1.5B、7B 和 14B 版,DeepSeek 模型通过 ONNX QDQ 格式进行优化,也可以直接通过 Azure AI Foundry 下载。
未来微软会将这些优化的模型推送给搭载英特尔和 AMD 且具有 NPU 单元的笔记本电脑,而不具备 NPU 单元的设备暂时无法使用此类人工智能。











